Neblina Insights: El Blog de IA
Manténgase al día sobre IA en las instalaciones, seguridad de datos y mejores prácticas de rendimiento.
¿Cloud o In-House? Cómo elegir la mejor infraestructura de AI
Guía comparativa de costos iniciales en la nube vs. control y seguridad a largo plazo con soluciones in-house de Neblina.
Leer Más
El Backup Esencial: Protegiendo tu Inversión en IA
Aprende la estrategia de triple pilar para asegurar tus activos de IA: datos brutos, pesos del modelo entrenado e infraestructura de ejecución local.
Leer Más
Escalabilidad y Aprendizaje: Patrones Avanzados (Parte 3)
Análisis de los patrones Reflexión y Eventual, necesarios para la autocorrección y escalabilidad horizontal de agentes locales.
Leer Más
10 Principios de Arquitectura para Agentes en Producción (Parte 2)
Las 10 reglas para mitigar el Model Drift, asegurar la seguridad y hacer la transición de piloto a producción fiable.
Leer Más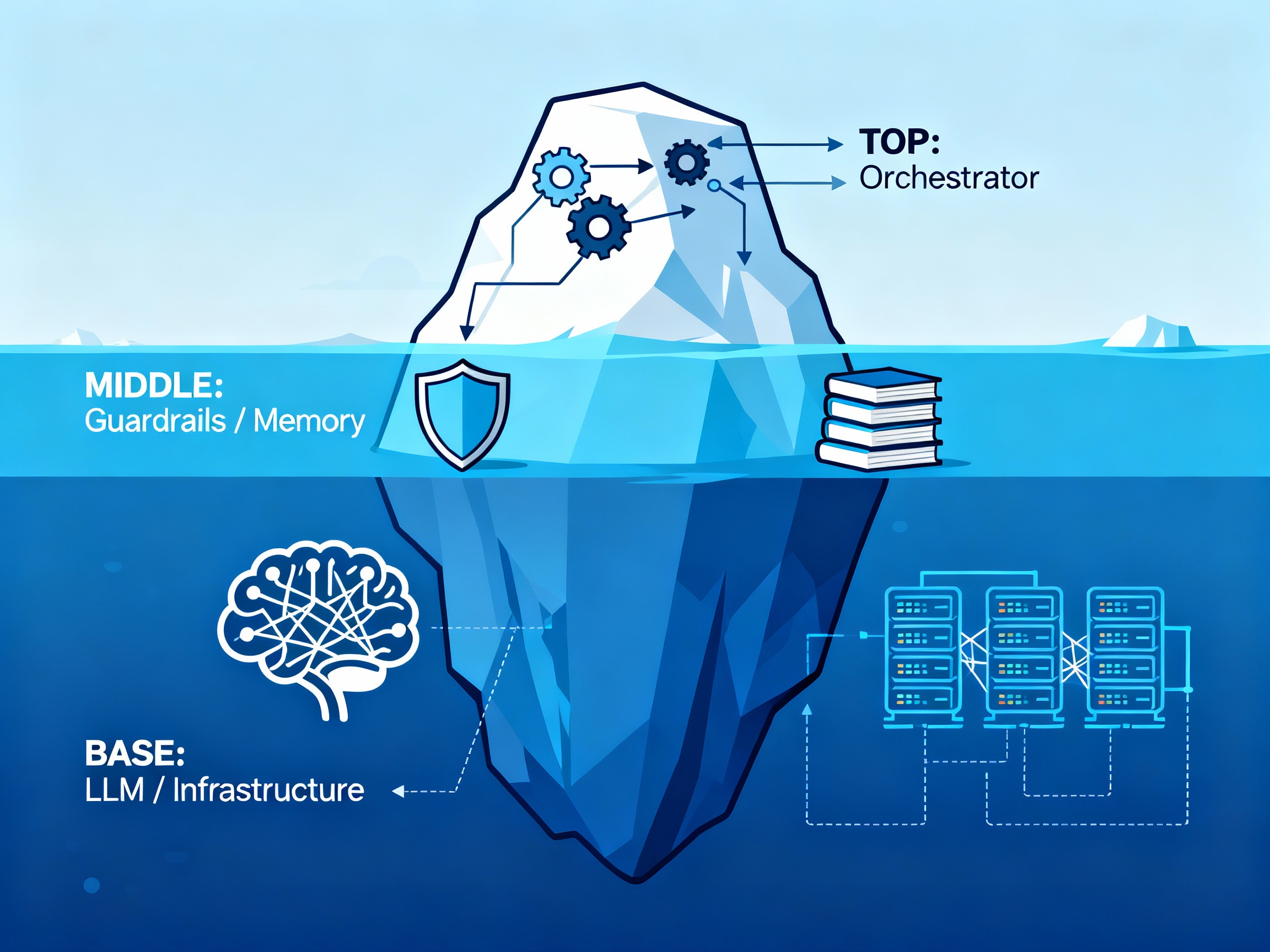
Mas que un Chatbot: Arquitectura para Agentes de IA para PyMEs (Parte 1)
Introducción a los Agentes de IA de Grado Empresarial y la Arquitectura del Iceberg (Orquestador, Memoria y componentes de Infraestructura).
Leer Más
IA Local: La Ventaja Competitiva en el Servicio al Cliente
La baja latencia y el acceso a datos privados permiten un soporte instantáneo e hiperpersonalizado y chatbots.
Leer Más
Entrenando LLMs Privados con Visión y Audio
Por qué los MLLMs requieren despliegue local para manejar de forma segura datos visuales y de audio sensibles y masivos.
Leer Más
Estrategia de Mantenimiento: Asegurando la Estabilidad
Comprenda MLOps y cómo el monitoreo local continuo y el reentrenamiento previenen el peligroso 'Model Drift'.
Leer Más
El Futuro de los LLMs: Ajuste Fino en Datos Privados
Descubra cómo Neblina le ayuda a personalizar grandes modelos de lenguaje para una precisión y relevancia inigualables con sus datos.
Leer Más
Por qué la IA en las Instalaciones Garantiza la Soberanía de los Datos
Explore las ventajas críticas de mantener sus datos y modelos sensibles dentro de su propia infraestructura privada.
Leer Más
Maximizando la Velocidad del Modelo: Latencia Local vs. Cloud
Una comparación detallada de los tiempos de respuesta y cómo la implementación local elimina los cuellos de botella de la red.
Leer Más